Python 变量不是盒子
首先看如下示例:
1 | a = [1, 2, 3] |
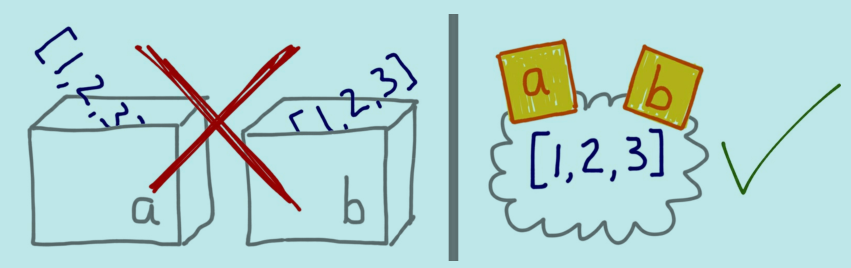
如果把变量想象为盒子,那么无法解释 Python 中的赋值,应该将变量视作”便利贴”(标注),这样如上示例就好解释了.
再看如下示例
1 | class Gizmo: |
Python 中的赋值语句,应该始终先读右边.对象在右边创建或获取,在此之后左边的变量才会绑定到对象上,这就像为对象贴上标注或为对象添加别名.
垃圾回收
对象绝不会自行销毁.但是,无法得到对象时,该对象可能会被当作垃圾回收
在 CPython 中,垃圾回收采用的机制是引用计数机制为主,标记-清除和分代回收为辅的策略.
实际上,Python 中的每个对象维护一个名为 ob_ref 的字段,用来记录该对象当前被引用的次数,每当新的引用指向该对象时,它的引用计数 ob_ref 加 1,每当该对象的引用失效时,计数 ob_ref 减 1.一旦对象的引用计数为 0,CPython 会在对象上调用 __del__ 方法(如果定义了),然后释放分配给对象的内存.
可以通过 sys.getrefcount() 函数查看对象的引用数量.
1 | class A(object): |
导致引用加减情况
如下情况下,引用计数会加 1
- 对象被创建,并为其添加别名(给变量贴上标签).如
a = A() - 对象为对象添加另一个别名.如
b = a - 对象被作为参数,传入到一个函数中.如
func(a) - 对象作为一个元素,存储在容器中.如
list1=[a,a]
如下情况下,引用计数会减 1
- 对象的别名被显式销毁.如
del a - 对象的别名被赋予新的对象.如
a = 24 - 对象离开它的作用域.如,
func函数执行完毕时,func函数中的局部变量及传入的参数(全局变量不会) - 对象所在的容器被销毁或从容器中删除对象.如
list1.remove(a)
引用计数机制的优缺点
优点
- 简单
- 实时性: 一旦没有引用,内存就直接释放了,不用像其他机制得等到特定时机.实时性还带来一个好处.处理回收内存的时间分摊到了平时
缺点
- 维护引用计数消耗资源
- 会出现循环引用问题
循环引用
循环引用是指当一个数据结构引用了它自身,即这个数据结构是个循环数据结构,那么它的引用计数值无法变为 0,也就是说这个数据结构占用的内存无法被自动回收
1 | aa = [1, 2] # aa 引用对象的引用计数 + 1 |
del aa 和 del bb 之后已经没有变量指向这个两个列表对象了,但是列表对象的引用计数却没有减少到零
为了解决对象的循环引用问题,Python 引入了标记-清除和分代回收两种垃圾回收机制.
标记-清除
循环引用的问题只有在容器对象之间才有可能发生,比如列表,字典,类,元组.
首先,为了追踪容器对象,需要每个容器对象维护两个额外的指针,用来将容器对象组成一个链表,指针分别指向前后两个容器对象,方便插入和删除操作.
标记-清除采用的方法是在不改动真实的引用计数的前提下,将集合中对象的引用计数复制一份副本,改动该对象引用的副本.对于副本做任何的改动,都不会影响到对象生命周期的维护.
第一步,通过计数副本寻找 root object 集合(该集合中的对象是不能被回收的).例如: aa 和 bb 的循环引用,首先找到循环引用的一端 aa,因为它有一个对 bb 的引用,则将 bb 的引用计数减1.然后顺着引用达到 bb,因为 bb 有一个对 aa 的引用,同样将 aa 的引用减 1,这样就完成了循环引用对象间环摘除,并且判断 aa, bb 是不是属于 root object 集合.
第二步,当成功寻找到 root object 集合之后,首先将现在的内存链表一分为二,一条链表中维护 root object 集合,成为 root 链表,而另外一条链表中维护剩下的对象,成为 unreachable 链表.之所以要剖成两个链表,是基于这样的一种考虑:现在的 unreachable 可能存在被root链表中的对象,直接或间接引用的对象,这些对象是不能被回收的(例如:aa 引用了 bb, 而 bb 没有引用 aa),一旦在标记的过程中,发现这样的对象,就将其从 unreachable 链表中移到 root 链表中;当完成标记后,unreachable链表中剩下的所有对象就是名副其实的垃圾对象了,接下来的垃圾回收只需限制在 unreachable 链表中即可.
“标记-清除”执行前需要复制一份副本,这种额外操作实际上与系统中总的内存块的数量是成正相关.当需要回收的内存块越多时,垃圾检测带来的额外操作就越多.
分代回收
分代回收是一种以空间换时间的操作方式,Python将内存根据对象的存活时间划分为不同的集合,每个集合称为一个代,Python将内存分为了 3 “代”,分别为年轻代(第0代),中年代(第1代),老年代(第2代),他们对应的是3个链表,它们的垃圾收集频率与对象的存活时间的增大而减小.新创建的对象都会分配在年轻代,年轻代链表的总数达到上限时,Python垃圾收集机制就会被触发,把那些可以被回收的对象回收掉,而那些不会回收的对象就会被移到中年代去,依此类推,老年代中的对象是存活时间最久的对象,甚至是存活于整个系统的生命周期内.
参考:

